在线阅读地址:https://junhuatechlog.github.io/keypoints
Ethernet Introduction
OSI定义了7层网络模型,在网络实现中,我们听到最多的是TCP/IP协议和Ethernet。Ethernet处在那一层呢? Ethernet是一个工作在数据链路层和物理层的协议。Ethernet又分成了哪几个子层?
- Link layer control/Media access control
- Phy:
- Physical coding layer (编码)
- Physical medium dependent(媒介)
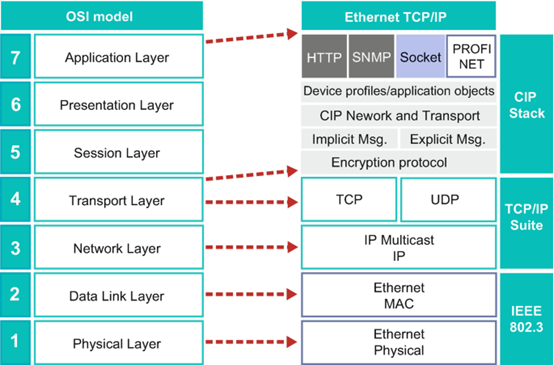
以太网简介
以太网是一种局域网联网技术,工作在数据链路层和物理层,由哈佛大学一名博士生(Bob Metcalfe, 后来创立了3Com)于20世纪70年代发明。 发明早期,以太网面临来自其他局域网技术(比如令牌环,FDDI, ATM)的竞争。但是,以太网技术也在不断更新迭代,演化发展,到现在已经成为最流行的有线局域网技术。可以说,以太网对本地区域联网的重要性就像因特网对全球联网所具有的地位那样。

以太网发展主要经历3个阶段
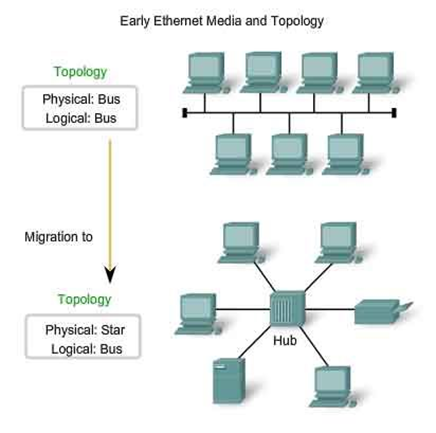
- 以太网早期(70年代), 使用同轴电缆总线来互联节点,是一种广播局域网,采用二进制指数回退(Binary exponential backoff)的CSMA/CD多路访问协议。
- 到20世纪90年代后期,开始流行使用基于集线器的星形拓扑以太网,集线器(Hub)是一种物理层设备,它作用于各个比特而不是作用于帧。因此,它依旧是一个广播局域网,无论何时从一个接口收到一个比特,它向其他所有接口发送该比特的副本。会发生碰撞,必须重新传输。
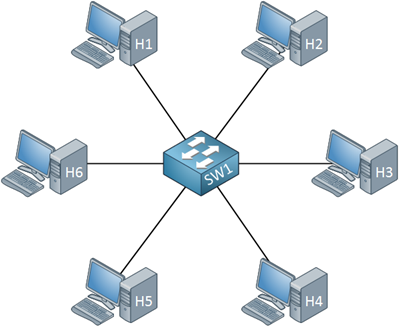
- 到21世纪初,出现一次重要的革命性变化,集线器换成了交换机(switch), 避免了碰撞,实现了存储转发分组。
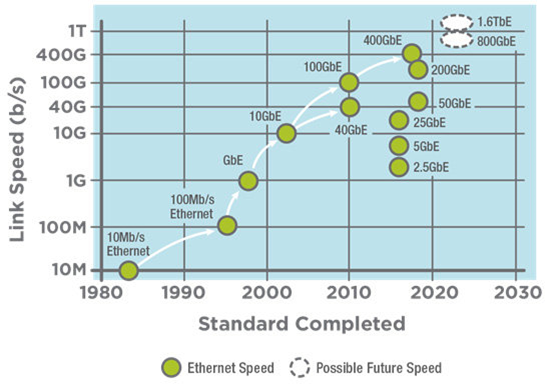
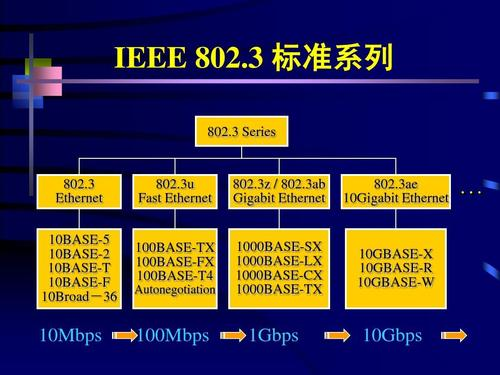
IEEE802 定义了局域网&城域网标准,而802.3定义了以太网标准,802.3实际上是一个以太网标准集,定义了很多和以太网相关的标准(不同的speed有对应的不同的标准,PoE(Power over Ethernet), 链路聚合, etc)。
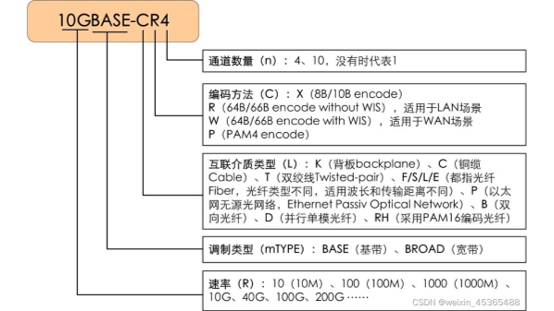
这些标准有什么不同呢? 后缀代表什么意思?
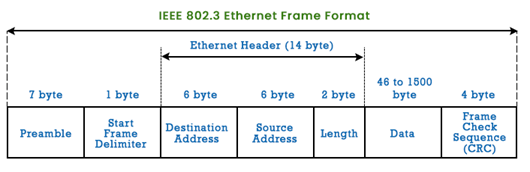
以太网帧结构
前同步码(8字节 Preamble): 以太网帧以一个8byte的前同步码(Preamble)字段开始, 前7bytes都是10101010,用于”唤醒”适配器,并且将它们的时钟和发送方的时钟同步,最后一个字节是10101011,最后2bit警告适配器,重要的内容要来了。
FCS(Frame Check Sequence): 通过CRC检测差错
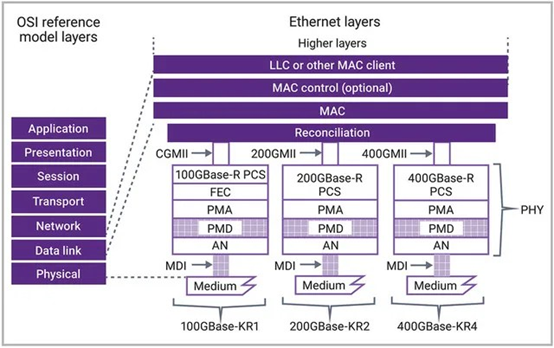
以太网的物理层:
因为交换机是即插即用的,链路层彼此隔离,所以主机和交换机可以用不同的链路连接,每个链路支持的物理介质(光纤, 同轴电缆, 双绞线, 电气背板)也可以不同,速率(1G, 10G, 100G)也可以不同。以太网定义了一些物理层标准:
VLAN(Virtual Local Area Network)
在一个局域网里可以有很多个计算机,他们用于处理不同的业务,比如HR部门正在讨论裁员,开发部门正在讨论代码, 财务部门正在讨论加薪。有些敏感的数据肯定不希望在整个局域网里传播,也不希望和不相关的部门在同一个局域网,这里有安全上的考虑。所以引入了虚拟局域网的概念。 VLAN由IEEE 802.1Q标准定义,在这个标准里定义了带vlan tagging的Ethernet frame。

Race condition while loading modules in parallel in kmod-18
- Race condition while loading modules in parallel in kmod-18
- Triger the bug method
- Function call procedure when calling 'modprobe'
- kmod_module_get_initstate() in kmod-18
- kmod_module_get_initstate() in kmod-20 - Correction
- Where the process blocked if module being mounted in parallel
Triger the bug method
3 processes/threads call modprobe to install same kernel module in parallel will cause the problem.
Function call procedure when calling 'modprobe'
Command modprobe xfrm_user.ko will call system call finit_module().
systemcall finit_module() in kernel/module.c
--> int load_module(struct load_info *info, const char __user *uargs, int flags)
int load_module(struct load_info *info, const char __user *uargs, int flags)
/* Link in to syfs. */
err = mod_sysfs_setup(mod, info, mod->kp, mod->num_kp);
if (err < 0)
goto bug_cleanup;
/* Get rid of temporary copy. */
free_copy(info);
/* Done! */
trace_module_load(mod);
return do_init_module(mod);
--> err = mod_sysfs_setup(mod, info, mod->kp, mod->num_kp);
static int mod_sysfs_setup(struct module *mod,
const struct load_info *info,
struct kernel_param *kparam,
unsigned int num_params)
...
err = mod_sysfs_init(mod);
if (err)
goto out;
mod->holders_dir = kobject_create_and_add("holders", &mod->mkobj.kobj);
if (!mod->holders_dir) {
err = -ENOMEM;
goto out_unreg;
}
err = module_param_sysfs_setup(mod, kparam, num_params);
if (err)
goto out_unreg_holders;
err = module_add_modinfo_attrs(mod);
if (err)
goto out_unreg_param;
add_usage_links(mod);
add_sect_attrs(mod, info);
add_notes_attrs(mod, info);
kobject_uevent(&mod->mkobj.kobj, KOBJ_ADD);
return 0;
mod_sysfs_init(mod) will add the xfrm_user to the kobject link table, means create the directory /sys/modules/xfrm_user.
module_param_sysfs_setup(mod, kparam, num_params); will create module's specific parameters in /sys/modules/xfrm_user/parameters/ directory.
module_add_modinfo_attrs(mod); will create uniform attributes for every kernel module.
static struct module_attribute *modinfo_attrs[] = {
&module_uevent,
&modinfo_version,
&modinfo_srcversion,
&modinfo_initstate,
&modinfo_coresize,
&modinfo_initsize,
&modinfo_taint,
#ifdef CONFIG_MODULE_UNLOAD
&modinfo_refcnt,
#endif
NULL,
};
static struct module_attribute modinfo_initstate =
__ATTR(initstate, 0444, show_initstate, NULL);
From above analysis, /sys/module/<module name> and /sys/module/<module name>/initstate creations are not atomic. There's a small window in which the directory exists but the initstate file was still not created.
This window cause the kmod modprobe logic error when check the module init state.
modprobe will check the kernel module initstate before call finit_module(), check initstate is done by function:kmod_module_get_initstate().
kmod_module_get_initstate() in kmod-18
KMOD_EXPORT int kmod_module_get_initstate(const struct kmod_module *mod)
pathlen = snprintf(path, sizeof(path),
"/sys/module/%s/initstate", mod->name);
fd = open(path, O_RDONLY|O_CLOEXEC);
if (fd < 0) {
err = -errno;
DBG(mod->ctx, "could not open '%s': %s\n",
path, strerror(-err));
if (pathlen > (int)sizeof("/initstate") - 1) {
struct stat st;
path[pathlen - (sizeof("/initstate") - 1)] = '\0';
if (stat(path, &st) == 0 && S_ISDIR(st.st_mode))
return KMOD_MODULE_BUILTIN;
}
DBG(mod->ctx, "could not open '%s': %s\n",
path, strerror(-err));
return err;
}
If the /sys/module/xfrm_user/initstate haven't created, but /sys/module/xfrm_user/ already there,
It will return KMOD_MODULE_BUILTIN; which means the kernel module are built in the kernel,
which actually is not ready.
kmod_module_get_initstate() in kmod-20 - Correction
To check if the modules are builtin, to check the /lib/modules/uname -r/modules.builtin
file instead of /sys/module/\<module name\>,
The modules.builtin file are created when kernel compilation in SCM phase.
static char *lookup_builtin_file(struct kmod_ctx *ctx, const char *name)
{
char *line;
if (ctx->indexes[KMOD_INDEX_MODULES_BUILTIN]) {
DBG(ctx, "use mmaped index '%s' modname=%s\n",
index_files[KMOD_INDEX_MODULES_BUILTIN].fn,
name);
line = index_mm_search(ctx->indexes[KMOD_INDEX_MODULES_BUILTIN],
name);
} else {
struct index_file *idx;
char fn[PATH_MAX];
snprintf(fn, sizeof(fn), "%s/%s.bin", ctx->dirname,
index_files[KMOD_INDEX_MODULES_BUILTIN].fn);
DBG(ctx, "file=%s modname=%s\n", fn, name);
idx = index_file_open(fn);
if (idx == NULL) {
DBG(ctx, "could not open builtin file '%s'\n", fn);
return NULL;
}
line = index_search(idx, name);
index_file_close(idx);
}
return line;
}
bool kmod_lookup_alias_is_builtin(struct kmod_ctx *ctx, const char *name)
{
_cleanup_free_ char *line;
line = lookup_builtin_file(ctx, name);
return line != NULL;
}
bool kmod_module_is_builtin(struct kmod_module *mod)
{
if (mod->builtin == KMOD_MODULE_BUILTIN_UNKNOWN) {
kmod_module_set_builtin(mod,
kmod_lookup_alias_is_builtin(mod->ctx, mod->name));
}
return mod->builtin == KMOD_MODULE_BUILTIN_YES;
}
/**
* kmod_module_get_initstate:
* @mod: kmod module
*
* Get the initstate of this @mod, as returned by Linux Kernel, by reading
* /sys filesystem.
*
* Returns: < 0 on error or module state if module is found in kernel, valid states are
* KMOD_MODULE_BUILTIN: module is builtin;
* KMOD_MODULE_LIVE: module is live in kernel;
* KMOD_MODULE_COMING: module is being loaded;
* KMOD_MODULE_GOING: module is being unloaded.
*/
KMOD_EXPORT int kmod_module_get_initstate(const struct kmod_module *mod)
{
char path[PATH_MAX], buf[32];
int fd, err, pathlen;
if (mod == NULL)
return -ENOENT;
/* remove const: this can only change internal state */
if (kmod_module_is_builtin((struct kmod_module *)mod))
return KMOD_MODULE_BUILTIN;
pathlen = snprintf(path, sizeof(path),
"/sys/module/%s/initstate", mod->name);
fd = open(path, O_RDONLY|O_CLOEXEC);
if (fd < 0) {
err = -errno;
DBG(mod->ctx, "could not open '%s': %s\n",
path, strerror(-err));
if (pathlen > (int)sizeof("/initstate") - 1) {
struct stat st;
path[pathlen - (sizeof("/initstate") - 1)] = '\0';
if (stat(path, &st) == 0 && S_ISDIR(st.st_mode))
return KMOD_MODULE_COMING;
}
DBG(mod->ctx, "could not open '%s': %s\n",
path, strerror(-err));
return err;
}
err = read_str_safe(fd, buf, sizeof(buf));
close(fd);
if (err < 0) {
ERR(mod->ctx, "could not read from '%s': %s\n",
path, strerror(-err));
return err;
}
if (streq(buf, "live\n"))
return KMOD_MODULE_LIVE;
else if (streq(buf, "coming\n"))
return KMOD_MODULE_COMING;
else if (streq(buf, "going\n"))
return KMOD_MODULE_GOING;
ERR(mod->ctx, "unknown %s: '%s'\n", path, buf);
return -EINVAL;
}
Race condition while loading modules in parallel in kmod-18 patch
kmod source code commit of the patch
Where the process blocked if module being mounted in parallel
If 3 threads call socket(AF_NETLINK, SOCK_RAW, NETLINK_XFRM); in parallel, which will trigger 3 modprobe processes start to load kernel module xfrm_user.ko. Only 1 unique process will load the module, other 2 processes should be blocked. Where the other 2 processes blocked?
From the kmod-20 code, we can get the dependency analysis in the kmod before loading modules, then load modules one by one according the dependency list by finit_module() system call.
It call finit_module() systemcall to load kernel modules. --> int load_module(struct load_info *info, const char __user *uargs, int flags)
static int load_module(struct load_info *info, const char __user *uargs, int flags)
{
struct module *mod;
long err;
err = module_sig_check(info);
if (err)
goto free_copy;
err = elf_header_check(info);
if (err)
goto free_copy;
/* Figure out module layout, and allocate all the memory. */
mod = layout_and_allocate(info, flags);
if (IS_ERR(mod)) {
err = PTR_ERR(mod);
goto free_copy;
}
/* Reserve our place in the list. */
err = add_unformed_module(mod);
if (err)
goto free_module;
...
/* Link in to syfs. */
err = mod_sysfs_setup(mod, info, mod->kp, mod->num_kp);
if (err < 0)
goto bug_cleanup;
/* Get rid of temporary copy. */
free_copy(info);
/* Done! */
trace_module_load(mod);
return do_init_module(mod);
...
}
In the add_unformed_module(mod), it will check if the module already installed.
/*
* We try to place it in the list now to make sure it's unique before
* we dedicate too many resources. In particular, temporary percpu
* memory exhaustion.
*/
static int add_unformed_module(struct module *mod)
{
int err;
struct module *old;
mod->state = MODULE_STATE_UNFORMED;
again:
mutex_lock(&module_mutex);
if ((old = find_module_all(mod->name, true)) != NULL) {
if (old->state == MODULE_STATE_COMING
|| old->state == MODULE_STATE_UNFORMED) {
/* Wait in case it fails to load. */
mutex_unlock(&module_mutex);
err = wait_event_interruptible(module_wq,
finished_loading(mod->name));
if (err)
goto out_unlocked;
goto again;
}
err = -EEXIST;
goto out;
}
list_add_rcu(&mod->list, &modules);
err = 0;
out:
mutex_unlock(&module_mutex);
out_unlocked:
return err;
}
There is a mutex module_mutex for this purpose, if the module already installed and state is LIVE, the finit_module() will return -EEXIST immediately. If the module is installing, state is not LIVE or GOING, the modprobe process will be blocked and put to wait queue(module_wq). It will be waked up if the module installation finish, or failed. If there is no same module name found from the modules list, the new module name will be added to the modules list, and go on to install the module.
Module state definition
During module installation, module's state was changed according to different phase.
include/linux/module.h
enum module_state {
MODULE_STATE_LIVE, /* Normal state. module initialize complete!*/
MODULE_STATE_COMING, /* Full formed, running module_init. */
MODULE_STATE_GOING, /* Going away. failed to initialize the module*/
MODULE_STATE_UNFORMED, /* Still setting it up. in the early phase*/
};
Function call procedure comparision
When the problem happens in kmod-18, the function call procedure is different to the procedure in kmod-20.
Take sockettest as an example, 3 threads will be created to call socket(),
which triggers 3 processes to install xfrm_user.ko module in parallel!
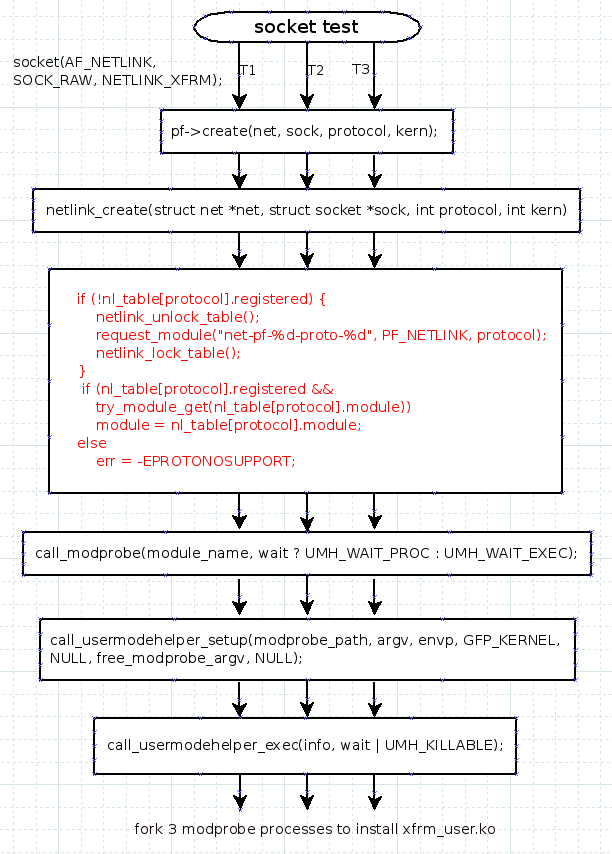
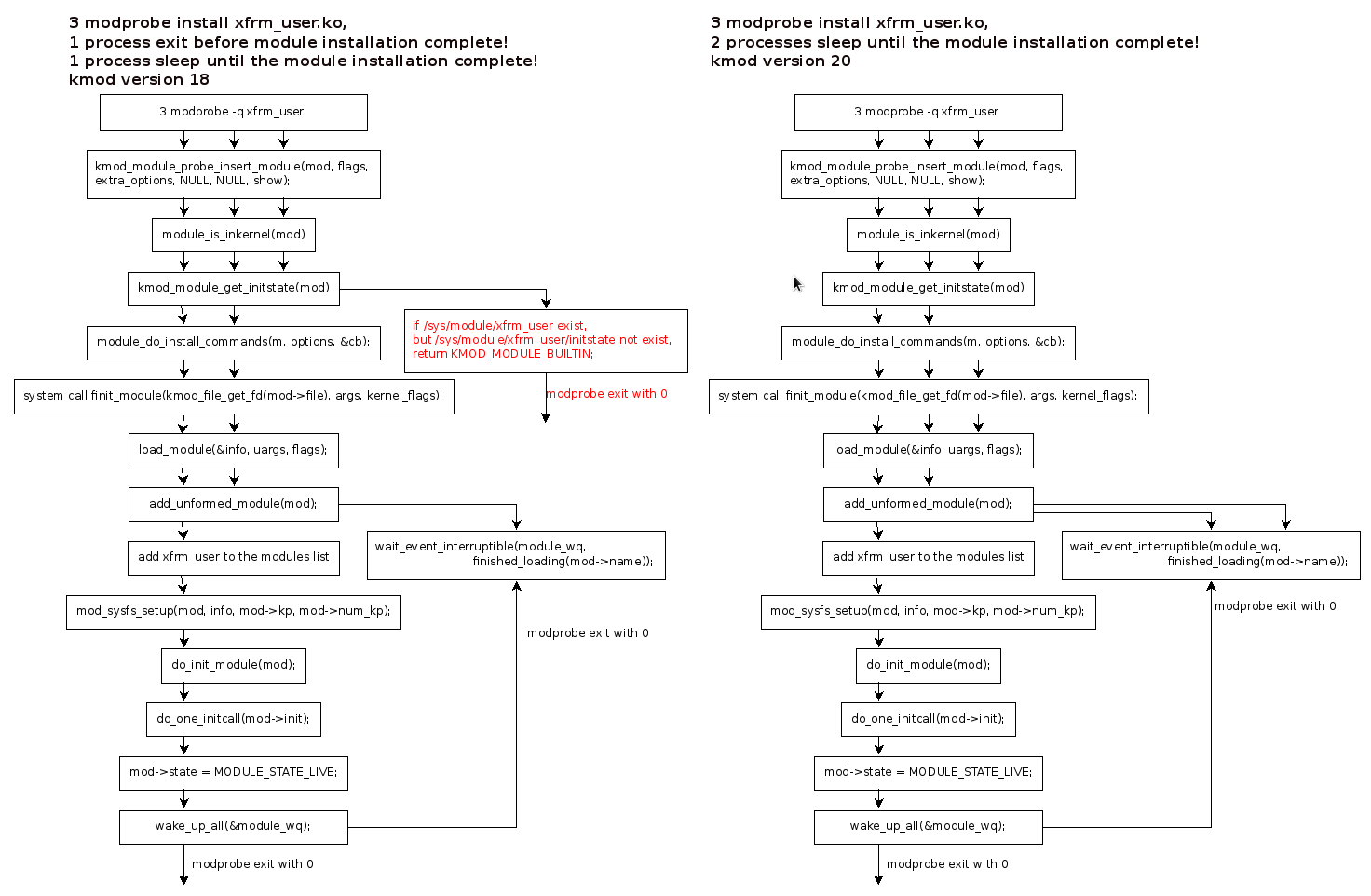
Debug print and patch to check where the processes are blocked
Because of the dependencies, install xfrm_usr.ko will install xfrm_algo.ko first, then xfrm_usr.ko. Debug logs:
[ 53.806738] IPv6: ADDRCONF(NETDEV_CHANGE): xaui2: link becomes ready
[ 69.516325] vrha: vrha_set_polling_mode : (ACTIVE)
[ 84.373189] finit_module: 2840, modprobe
[ 84.373344] unformed module: 2840, modprobe, mod name: xfrm_algo
[ 84.373366] finit_module: 2846, modprobe
[ 84.373476] unformed module: 2846, modprobe, mod name: xfrm_algo
[ 84.373480] finit_module: 2843, modprobe
[ 84.373768] wait in the module_wq: 2846, modprobe
[ 84.373790] unformed module: 2843, modprobe, mod name: xfrm_algo
[ 84.373798] wait in the module_wq: 2843, modprobe
[ 84.373888] call module init 2840, modprobe, xfrm_algo!
[ 84.373912] mod xfrm_algo already exist! 2846, modprobe
[ 84.373924] mod xfrm_algo already exist! 2843, modprobe
[ 84.373970] finit_module: 2840, modprobe
[ 84.373992] finit_module: 2846, modprobe
[ 84.374003] finit_module: 2843, modprobe
[ 84.374129] unformed module: 2843, modprobe, mod name: xfrm_user
[ 84.374137] unformed module: 2846, modprobe, mod name: xfrm_user
[ 84.374143] unformed module: 2840, modprobe, mod name: xfrm_user
[ 84.374149] wait in the module_wq: 2843, modprobe
[ 84.374178] wait in the module_wq: 2840, modprobe
[ 84.374641] call module init 2846, modprobe, xfrm_user!
[ 84.374659] Initializing XFRM netlink socket
[ 84.374704] mod xfrm_user already exist! 2843, modprobe
[ 84.374791] mod xfrm_user already exist! 2840, modprobe
finit_module() function
int finit_module(int fd, const char *param_values,
int flags);
Reads the module to be loaded from the file descriptor fd into kernel space, performs any necessary symbol relocations, then, check if the module already installed, setup sysfs directory for the module, initializes module parameters to values provided by the caller, and then runs the module's init function.
M314
- Mansho Descritpion
- Analysis
- Function call analysis
- xfrm_user_init procedure
- Zhou Libing Analysis
- Idea get from David Meng
Mansho 314 Description
When trs call socket() to create a XFRM netlink, it return error number 120, means 'Protocol not supported'.
Error logs:
1011-0-CCS <2013-01-01T00:00:47.224434Z> ECB-LinuxListener ERR/LFS/LinuxSyslog, trsXfrmBridge[5369]: XFRM: XfrmBridgeMessageDispatcher::isConnected() socket creation failed. errno=120 = 'Protocol not supported'
1011-0-CCS <2013-01-01T00:00:47.362647Z> ECB-LinuxListener INF/LFS/LinuxSyslog, kernel: [ 66.117384] Initializing XFRM netlink socket
Analysis
Found the xfrm_user.ko/xfrm_algo.ko are loaded when the socket() with NETLINK_XFRM called, "Initializing XFRM netlink socket" will be printed when the xfrm_user_init() is executed.
We suspect there is some race condition when the socket() function is called, maybe 2 process call socket() paralely? But now, don't have time to find RC, trs need us to build the kernel module in the kernel to avoid the problem.
Test Env:
Initializing XFRM netlink socket. 10.68.248.83; test/test2008
[junhuawa@hzling40]$cat lcpa.config |grep XFRM
CONFIG_XFRM=y
CONFIG_XFRM_ALGO=m
CONFIG_XFRM_USER=m
# CONFIG_XFRM_SUB_POLICY is not set
# CONFIG_XFRM_MIGRATE is not set
CONFIG_XFRM_STATISTICS=y
CONFIG_XFRM_IPCOMP=m
CONFIG_INET_XFRM_TUNNEL=m
CONFIG_INET_XFRM_MODE_TRANSPORT=m
CONFIG_INET_XFRM_MODE_TUNNEL=m
CONFIG_INET_XFRM_MODE_BEET=m
CONFIG_INET6_XFRM_TUNNEL=m
CONFIG_INET6_XFRM_MODE_TRANSPORT=m
CONFIG_INET6_XFRM_MODE_TUNNEL=m
CONFIG_INET6_XFRM_MODE_BEET=m
# CONFIG_INET6_XFRM_MODE_ROUTEOPTIMIZATION is not set
# CONFIG_SECURITY_NETWORK_XFRM is not set
Board's kernel configuration are stored in dir /var/fpwork1/junhuawa/XXX/src-bos/src/kernel/configs.
Log from my Redhat PC:
[ 2.160267] usbcore: registered new interface driver usbhid
[ 2.160269] usbhid: USB HID core driver
[ 2.160328] drop_monitor: Initializing network drop monitor service
[ 2.160485] TCP: cubic registered
[ 2.160495] Initializing XFRM netlink socket
[ 2.160655] NET: Registered protocol family 10
[ 2.161060] NET: Registered protocol family 17
[ 2.161644] Loading compiled-in X.509 certificates
[ 2.163061] Loaded X.509 cert 'Red Hat Enterprise Linux Driver Update Program (key 3): bf57f3e87362bc7229d9f465321773dfd1f77a80'
[ 2.164414] Loaded X.509 cert 'Red Hat Enterprise Linux kpatch signing key: 4d38fd864ebe18c5f0b72e3852e2014c3a676fc8'
[ 2.165771] Loaded X.509 cert 'Red Hat Enterprise Linux kernel signing key: 20a9713c3a76dc805fca64027c48c34de8fae907'
[ 2.165818] registered taskstats version 1
[junhuawa@Tesla ~]$ cat /boot/config-3.10.0-327.el7.x86_64 |grep XFRM
CONFIG_XFRM=y
CONFIG_XFRM_ALGO=y
CONFIG_XFRM_USER=y
CONFIG_XFRM_SUB_POLICY=y
CONFIG_XFRM_MIGRATE=y
CONFIG_XFRM_STATISTICS=y
CONFIG_XFRM_IPCOMP=m
CONFIG_INET_XFRM_TUNNEL=m
CONFIG_INET_XFRM_MODE_TRANSPORT=m
CONFIG_INET_XFRM_MODE_TUNNEL=m
CONFIG_INET_XFRM_MODE_BEET=m
CONFIG_INET6_XFRM_TUNNEL=m
CONFIG_INET6_XFRM_MODE_TRANSPORT=m
CONFIG_INET6_XFRM_MODE_TUNNEL=m
CONFIG_INET6_XFRM_MODE_BEET=m
CONFIG_INET6_XFRM_MODE_ROUTEOPTIMIZATION=m
CONFIG_SECURITY_NETWORK_XFRM=y
The xfrm_user/algo already built in kernel.
Map between kernel module names and systematic designations:
/lib/modules/$VERSION/modules.alias
sh-4.3# cat /lib/modules/3.10.64--fblrclcplfs15120061-lcpa/modules.alias |more
# Aliases extracted from modules themselves.
alias nfs-layouttype4-1 nfs_layout_nfsv41_files
alias fs-cramfs cramfs
alias fs-nfsd nfsd
alias devname:fuse fuse
alias char-major-10-229 fuse
alias fs-fuseblk fuse
alias fs-fuse fuse
alias fs-fusectl fuse
alias fs-pramfs pramfs
alias cipher_null crypto_null
alias digest_null crypto_null
alias compress_null crypto_null
alias sha1 sha1_generic
alias sha256 sha256_generic
alias sha224 sha256_generic
alias des des_generic
alias des3_ede des_generic
alias blowfish blowfish_generic
alias stdrng ansi_cprng
alias i2c:tca6424 gpio_pca953x
alias i2c:tca6416 gpio_pca953x
alias i2c:tca6408 gpio_pca953x
......
Builtin kernel modules list:
/lib/modules/$VERSION/modules.builtin
[junhuawa@Tesla pronto]$ cat /lib/modules/3.10.0-327.22.2.el7.x86_64/modules.builtin|grep xfrm
kernel/net/xfrm/xfrm_algo.ko
kernel/net/xfrm/xfrm_user.ko
Create socket link, and call is_connect() to check if link is ok, return "protocol is not supported!". Check when the xfrm_user.ko kernel module is loaded since it's not compiled into the kernel.
Calling socket function
s = socket(AF_NETLINK, SOCK_RAW, NETLINK_XFRM);
#define EPROTONOSUPPORT 120 /* Protocol not supported */
Call socket() will load the required kernel module automatically:
/net/socket.c
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
/* Now protected by module ref count */
rcu_read_unlock();
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
net/netlink/af_netlink.c
static int netlink_create(struct net *net, struct socket *sock, int protocol, int kern)
netlink_lock_table();
#ifdef CONFIG_MODULES
if (!nl_table[protocol].registered) {
netlink_unlock_table();
request_module("net-pf-%d-proto-%d", PF_NETLINK, protocol);
netlink_lock_table();
}
#endif
if (nl_table[protocol].registered &&
try_module_get(nl_table[protocol].module))
module = nl_table[protocol].module;
else
err = -EPROTONOSUPPORT;
It will check the nl_table[] if the protocol have been registered, if not, it will install the net-pf-16-proto-6 kernel module(xfrm_user.ko). If the protocol is still not registered, error code 120 will be returned.
static const struct net_proto_family netlink_family_ops = {
.family = PF_NETLINK,
.create = netlink_create,
.owner = THIS_MODULE, /* for consistency 8) */
};
--> kernel/kmod.c
request_module("net-pf-%d", family);
/include/linux/kmod.h
#define request_module(mod...) __request_module(true, mod)
--> ret = call_modprobe(module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC);
-> call_usermodehelper_setup() to initialize the workqueue
-> call_usermodehelper_exec() to wait until the user process(modprobe) execute complete!
xfrm_user_init procedure
xfrm_user_init ->
register_pernet_subsys(&xfrm_user_net_ops) // in net/core/net_namespace.c
-> register_pernet_operations(first_device, ops)
-> __register_pernet_operations(list, ops)
-> ops_init
-> ops->init(net) <--> xfrm_user_net_init(struct net *net)
-> netlink_kernel_create(net, NETLINK_XFRM, &cfg)
-> __netlink_kernel_create() in net/netlink/af_netlink.c
-> it will set the nl_table[unit].registered to 1.
ZhouLB Analysis based on debug print
Add debug print process name/pid in socket() interface, found there are at least 2 threads/process call the socket() to create XFRM netlink in parallel.
[ 77.930186] ++++++ xfrm_user_net_init1 by pid:6418, task:modprobe+++++ +^M
[ 77.937287] ++++++ xfrm_user_net_init done by pid:6418, task:modprobe+++++ +^M
[ 77.945354] ++++++ request_module done:netlink_create by pid:5409, task:trsKeyRetrieve++++++^M
[ 77.945427] ++++++ request_module done:netlink_create by pid:5373, task:trsXfrmBridge++++++^M
[ 77.946869] ++++++ xfrm_user_net_init1 by pid:6419, task:vsftpd+++++ +^M
[ 77.946881] ++++++ xfrm_user_net_init done by pid:6419, task:vsftpd+++++ +^M
Based on this found, he write a simple program to test create socket by 3 threads in parallel.
By this test program, the problem can be reproduced easily.
Debugging in the linux kernel
By debugging in the kernel code, we found when 3 threads call socket() to let it call userspace process modprobe to load the kernel module. 3 threads will wait until the initialized work be complete.
But sometimes, after the register_pernet_subsys() call end, 1-2 threads will return from wait immediately, the request_module() call end, it check if the protocol registered, found not, so, errno 120 is return.
Idea get from DavidM
He have known there is a race condition in the kmod source code, and has been patched in the latest kmod version.
The OS can reproduce the case have kmod version 18, but in my Redhat/CentOS7, can't reproduce the case because kmod version is 20.
From the patch got from kmod git repo, it already show there exist race condition in kmod-18 and older versions.
Use kmod version 21 in product, test 10000 times, can't reproduce the problem.
kmod source code commit of the patch
NETLINK
Kernel-user communication protocol.
Supported Address families, defined in /linux/socket.h AF_NETLINK:
Communication between kernel and user space. Datagram-oriented service.
AF_UNIX:
For local inter-porcess communication
PF_NETLINK: Protocol families, same as address families.
register_pernet_subsys - register a network namespace subsystem
Reset Safe Ram Disk
rpram: reset safe ram disk
/src-rfs/src/rootfs/systemd/rpram.service
ExecStart=/etc/init.d/ramdisk
phram MTD devices
dev_nvrd_name="/dev/nvrd"
fsck_logfile="/fsck.nvrd.log"
fsck_ret_value="/fsck.ret"
# do the check in a subshell and store the return value in a file
( fsck.ext4 -y -f $dev_nvrd_name &> $fsck_logfile; echo $? > ${fsck_ret_value}; ) &
fsck_pid=$!
mount -o bind /nvrd/log /var/log
mount -o bind /nvrd/tmp /var/tmp
ext4 usese hash table tree(HTREE) for directory organization and the extents organization. Check if hash tree enabled: tune2fs -l /dev/sde3 | grep dir_index
-bash-4.3# tune2fs -l /dev/nvrd
tune2fs 1.42.11 (09-Jul-2014)
Filesystem volume name: var
Last mounted on: /var/log
Filesystem UUID: ffc73ec9-b5fc-431c-8971-cb950f9e42f1
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype extent flex_bg sparse_super huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: not clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 16384
Block count: 65536
Reserved block count: 3276
Free blocks: 41422
Free inodes: 16129
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 255
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2048
Inode blocks per group: 256
Flex block group size: 16
Filesystem created: Tue Jan 1 00:00:02 2013
Last mount time: Tue Jan 1 00:00:01 2013
Last write time: Tue Jan 1 00:00:01 2013
Mount count: 1
Maximum mount count: -1
Last checked: Tue Jan 1 00:00:00 2013
Check interval: 0 (<none>)
Lifetime writes: 13 MB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Default directory hash: half_md4
Directory Hash Seed: c6f0671c-cd32-4c35-aa4f-48ec91fc877c
Journal backup: inode blocks
Pronto phenomenon:
nvrd.log:
-
log: Problem in HTREE directory inode 50 (/tmp/hwapi): bad block number 3. Clear HTree index? yes
-
log: Pass 2: Checking directory structure Entry 'tuningHistory.log' in /tmp (2049) references inode 151 found in group 0's unused inodes area. Fix? yes
Problem in HTREE directory inode 50 (/tmp/hwapi): bad block number 3. Clear HTree index? yes
Restarting e2fsck from the beginning... One or more block group descriptor checksums are invalid. Fix? yes
hwapi log:
Line 2486: 51000 002486 18.08 20:55:29.864502956 [192.168.129.2] 17 P-1111-0-HWRRese <2016-08-18T11:43:24.742445Z> DE0-RSTMain INF/HWA/RESET, ApiResetRpramSet: Writing 0x10110930 : to /var/tmp/hwapi/RP_RAM_hdbde_test_mode.txt
Pass 2: Checking directory structure
Entry test1233.log in /tmp/hwapi (66) has deleted/unused inode 52. Clear? yes
http://man7.org/linux/man-pages/man5/ext4.5.html
has_journal
Create a journal to ensure filesystem consistency even across
unclean shutdowns. Setting the filesystem feature is
equivalent to using the -j option with mke2fs or tune2fs.
This feature is supported by ext3 and ext4, and ignored by the
ext2 file system driver.
Journal checksumming
The journal is the most used part of the disk, making the blocks that form part of it more prone to hardware failure. And recovering from a corrupted journal can lead to massive corruption. Ext4 checksums the journal data to know if the journal blocks are failing or corrupted. But journal checksumming has a bonus: it allows one to convert the two-phase commit system of Ext3's journaling to a single phase, speeding the filesystem operation up to 20% in some cases - so reliability and performance are improved at the same time. (Note: the part of the feature that improves the performance, the asynchronous logging, is turned off by default for now, and will be enabled in future releases, when its reliability improves) "No Journaling" mode
Journaling ensures the integrity of the filesystem by keeping a log of the ongoing disk changes. However, it is known to have a small overhead. Some people with special requirements and workloads can run without a journal and its integrity advantages. In Ext4 the journaling feature can be disabled, which provides a small performance improvement.
In a journaling filesystem a special file called a journal is used to repair any inconsistencies caused due to improper shutdown of a system
https://en.wikipedia.org/wiki/Ext3#Journaling_levels
data={journal|ordered|writeback}
Specifies the journaling mode for file data. Metadata is
always journaled. To use modes other than ordered on the root
filesystem, pass the mode to the kernel as boot parameter,
e.g. rootflags=data=journal.
journal
All data is committed into the journal prior to being
written into the main filesystem.
ordered
This is the default mode. All data is forced directly
out to the main file system prior to its metadata being
committed to the journal.
writeback
Data ordering is not preserved ????data may be written
into the main filesystem after its metadata has been
committed to the journal. This is rumoured to be the
highest-throughput option. It guarantees internal
filesystem integrity, however it can allow old data to
appear in files after a crash and journal recovery.
mount -t ext4 -o sync,rw,noatime,exec,data=writeback $dev_nvrd $nvrd_mp
mount options:
sync All I/O to the filesystem should be done synchronously. In case of media with limited number of write cycles (e.g. some flash drives) "sync" may cause life-cycle shortening.
write-caching disabled, you can safely disable write barriers at mount time using the -o nobarrier option for mount
Mount options for ext4
barrier=none / barrier=flush
This enables/disables the use of write barriers in the journaling code. barrier=none disables it, barrier=flush enables it. Write barriers enforce proper
on-disk ordering of journal commits, making volatile disk write caches safe to use, at some performance penalty. The reiserfs filesystem does not enable
write barriers by default. Be sure to enable barriers unless your disks are battery-backed one way or another. Otherwise you risk filesystem corruption in
case of power failure.
fsync()/sync maybe can solve the problem
fsync, fdatasync - synchronize a file's in-core state with storage device
fsync() transfers ("flushes") all modified in-core data of (i.e., modified buffer cache pages for) the file referred to by the file descriptor fd to the disk device (or other permanent storage device) so that all changed information can be retrieved even after the system crashed or was rebooted. This includes writing through or flushing a disk cache if present. The call blocks until the device reports that the transfer has completed. It also flushes metadata information associated with the file (see stat(2)).
Difference between fflush(), fsync() and sync
fflush() works on FILE* , it just flushes the internal buffers in the FILE* of your application out to the OS.
fsync works on a lower level, it tells the OS to flush its buffers to the physical media.
OSs heavily caches data you write to a file. If the OS enforced every write to hit the drive, things would be very slow. fsync(among other things) allows you to control when the data should hit the drive.
Furthermore, fsync works on a file descriptor. It has no knowledge of a FILE* and can't flush its buffers. FILE* lives in your application, file descriptors lives in the OS kernel, typically.
To force the commitment of recent changes to disk, use the sync() or fsync() functions.
fsync() will synchronize all of the given file's data and metadata with the permanent storage device. It should be called just before the corresponding file has been closed.
sync() will commit all modified files to disk.
fdatasync与fsync的区别在于fdatasync不会flush文件的metadata信息。这个是为了减少对磁盘的操作。 If the underlying hard disk has write caching enabled , then the data may not really be on permanent storage when fsync() / fdatasync() return(4.3BSD, POSIX.1-2001). 但是在我的linux系统man里,没有发现这句话。
总的来说, fflush()只是将流刷出application到OS,不一定到disk, fsync()将特定文件(fd)刷到disk,sync()就是刷所有文件了。